NGUYEN QUANG VINH
Open Menu
Close Menu
Bio
Papers
Talks
News
Experience
Projects
Teaching
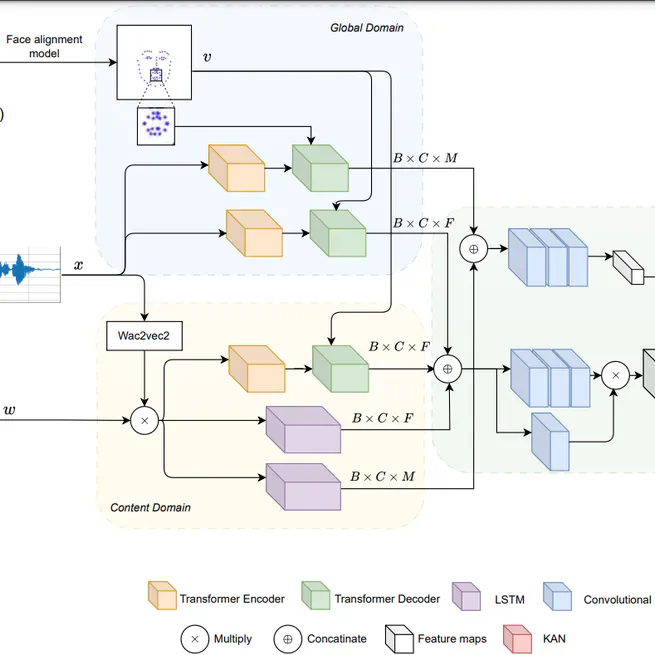
Audio-Driven Facial Landmarks Generation
KAN-Based Fusion of Dual-Domain for Audio-Driven Facial Landmarks Generation
Sep 9, 2024