Individual Audio-Driven Talking Head Generation based on Sequence of Landmark
Oct 31, 2024· ,,,,·
0 min read
,,,,·
0 min read
Son Hoang Thanh Vo
Nguyen Quang Vinh
Hyung Jeong Yang
Jieun Shin
Seungwon Kim
Soo Hyung Kim
Abstract
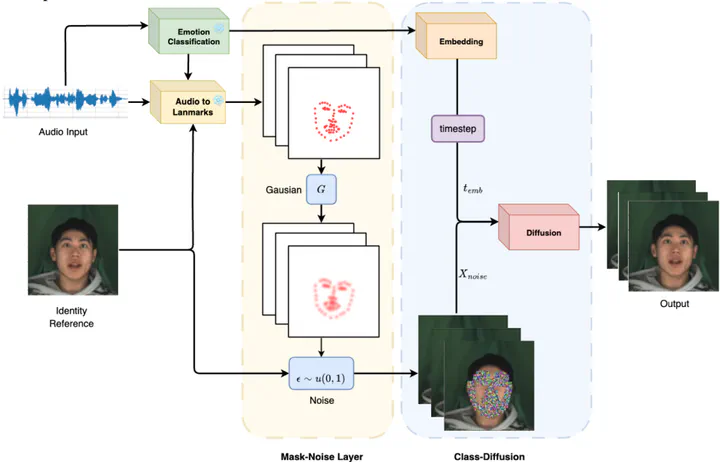
Talking Head Generation is a highly practical task that is closely tied to current technology and has a wide range of applications in everyday life. This technology will be of great help in the fields of photography, online conversation as well as in education and medicine. In this paper, the authors proposed a novel approach for Individual Audio-Driven Talking Head Generation by leveraging a sequence of landmarks and employing a diffusion model for image reconstruction. Building upon previous landmark-based methods and advancements in generative models, the authors introduce an optimized noise addition technique designed to enhance the model’s ability to learn temporal information from input data. The proposed method outperforms recent approaches in metrics such as Landmark Distance (LD) and Structural Similarity Index Measure (SSIM), demonstrating the effectiveness of the diffusion model in this domain. However, there are still challenges in optimization. The paper conducts ablation studies to identify these issues and outlines directions for future development.
Type
Publication
In Annual Conference of KIPS 2024